I’ve been working for a big Ad Tech enterprise (manages ~$2B in media spend and deploys campaigns in 70 markets, clients portfolio including: Google, Viber, etc). The company had a huge amount of data, and faced challenges with its volumes.
It was a long journey with a variety of solutions developed during it. I described some of the most memorable and interesting in the solutions section.
Background
My cozy office in Lviv, 2017
It was mid 2017. I was 21yo with experience of being self-employed for 6 years, 3 of which I had been building my IT company (service/consulting) with a cozy office downtown.
My experience ranged from short advice calls to a big 6 year development project. I enjoyed working with a wide variety of industries and organizations. Dozens of businesses and development processes were optimized during our cooperation. It makes me happy even today when I can name that period “old days”.
However, I felt that the process and business model which I had been developing was not quite efficient in the scaling. The main problem - I worked more hours per day than common sense permits.
The decision was made to do sole engineering for some time, without any other activities like client engagement, risk management, invoicing, etc. At the same time, working as an engineer in a typical IT company was an excellent opportunity to discover and analyze a business model that works (for years), find good organizational patterns, explore the corporation’s inefficiency, etc.
I chose a service IT company that provides consulting and development to companies at different scales - starting from young startups to big giants like Microsoft, Airbnb, McKinsey, and others.
Hiring
I lived in Lviv, and visiting tech talks was my regular activity. Morning at Lohika was one of the best tech talks in Lviv for ~5 years (in my point of view, of course).

Me at Morning@Lohika long time ago
I had been receiving job offers for a while. However, when I received email from the Lohika recruiters, I decided that it would be one of the first companies to apply. Though the interview is a stressful process, it was slightly compensated by my feeling of familiarity with Lohika's office.
We had a productive engagement cycle, including a few interviewing sessions resulting in an offer to become a data engineer in a big Ad Tech enterprise. I accepted the offer.

Morning@Lohika
Solutions
Data materialization engine
We built a semantic layer based on the source data using a Looker (BI tool with ETL capacities). In other words, on top of the database, we had a data wrapper layer. It was responsible for the data representation, transformation, and combination using SQL. When you work with big data settings, the execution time of a query becomes a problem due to the amount of data.
An old well-known approach to minimize this problem is to use materialized views. The main idea is to save data after transformation and give it to users instead of performing heavy transformations on the fly. It's named a materialized view as we save data in a temporary table named view.
Data materialization engine
Almost all common (relational) databases provide capacities to create materialized views. However, in our setting, we needed to save partitioned data using Presto, and it was a problem without an existing solution.
When our team faced this problem, I was responsible for solution design and development. I've used python and Google Cloud stack to implement needed capacities. After all, we improved performance queries for 20-60% (dependence on the client's data amount).
The created solution successfully processes the gigabytes of information per day for years now.
Tech stack: presto, python, hive, looker, google compute engine, fluentd, stackdriver.
Cloud Composer (Apache Airflow) Investigation
A distributed system for (big) data ingestion and processing was developed. The key ideology of the system was to make all components light and “slim”. It was built to get, validate, and save huge amounts of data in the data lake. As load data in the data lake is not an end of the data flow, we needed to prepare (transform, aggregate, calculate business metrics) it for our end consumers: analysts, marketers, managers.
We had a few options to do data transformation. Our choice was to use Airflow (workflow management platform) managed by Google (Cloud Composer) to orchestrate data transformation workflows.
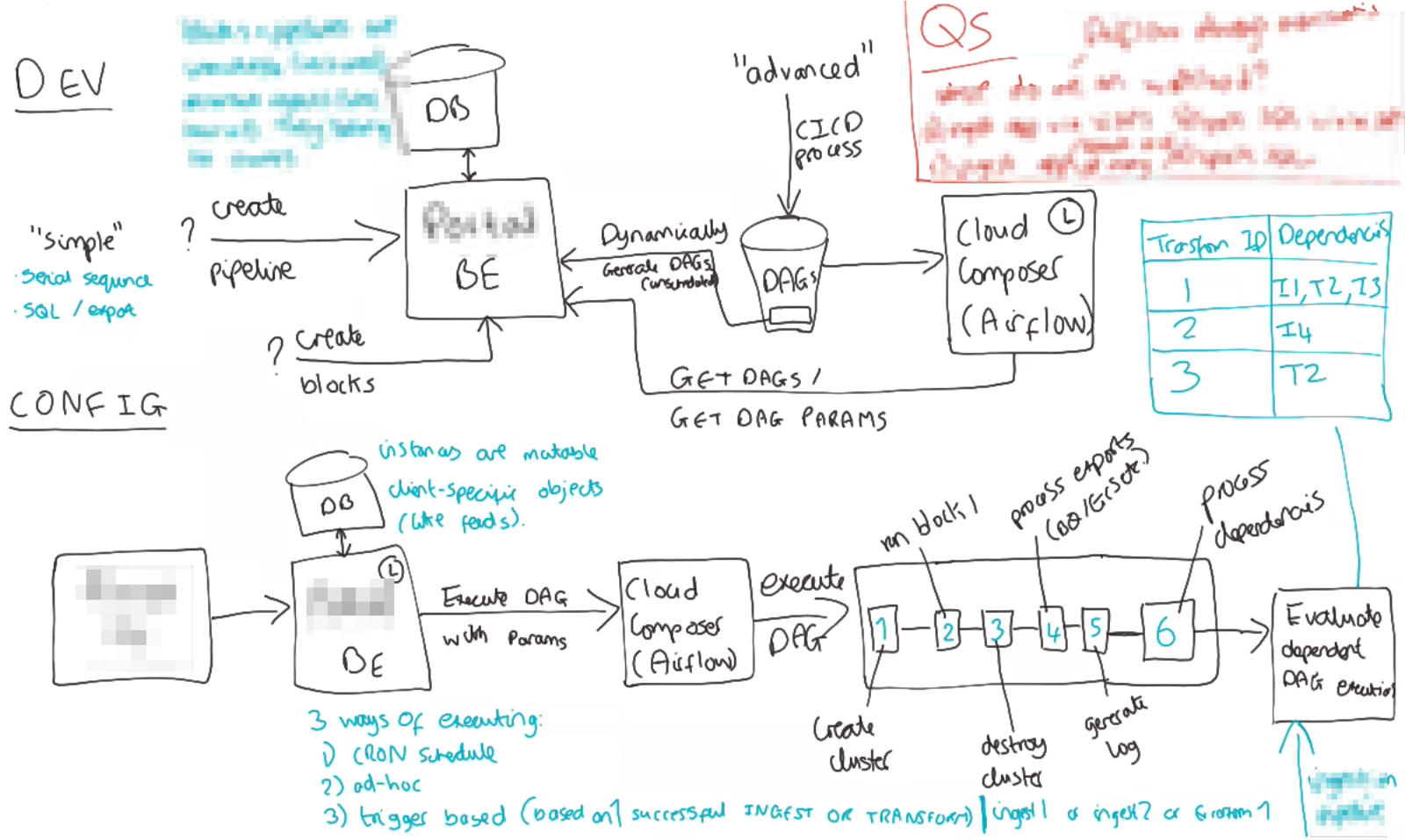
Data transformation draft system diagram
In the scope of the investigation, my objectives were the following:
- to validate that Cloud Composer is a tool that can be applied for data transformation needs as we wanted to be sure about component behavior and stability in the specific setting;
- find configuration for Cloud Composer to assure behavior which we want to have in the production system.
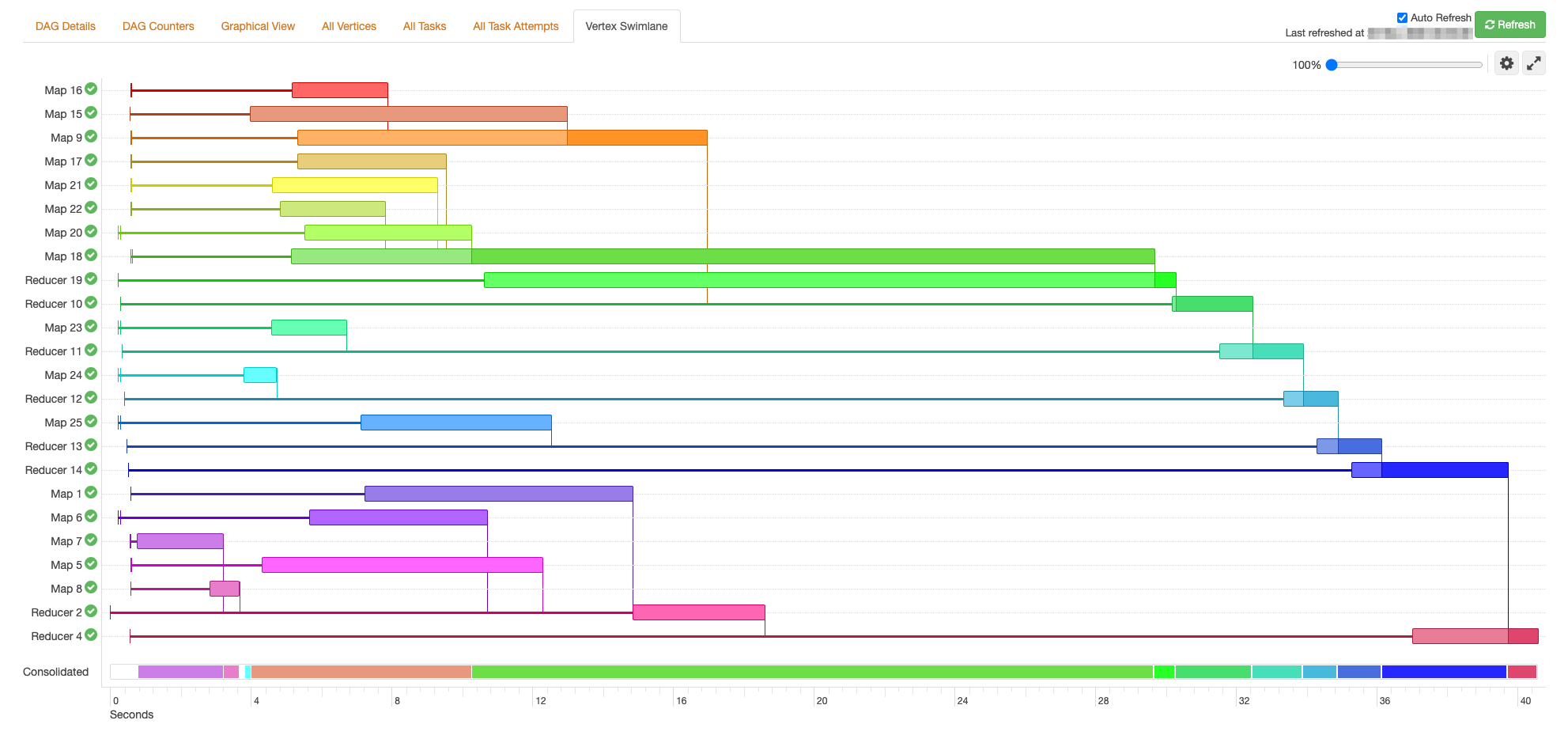
Data transformation tasks execution diagram
During this investigation, I found a way to patch Cloud Composer to make it vertically and horizontally scalable using a few Kubernetes tricks.
Tech stack: presto, airflow, python, kubernetes (k8s), google cloud composer.
CI/CD pipelines
Our team was responsible for the typical software life cycle - creating a new product, rapidly developing it, productizing, and maintaining. Since the team was not responsible for spinning up solutions, all stages were supposed to be done on top of existing solutions.
We sometimes received/used a production system without any/good CI (continuous integration) workflow due to different reasons. Such pipelines are an integral part of the “healthy” project lifecycle. In other words, we had a solution, and we were adding or changing it weekly or daily, however we didn’t have a sustainable system to check if our changes didn’t break anything.
An efficient CI/CD pipeline is a thing that you want to have in a situation where you need to deliver changes periodically (nowadays, release per feature pattern tells about a well-built delivery process).
I built a few pipelines for BI reports, data wrappers, and python solutions. Once, we used Jenkins (automation server), though mostly I’ve implemented CI pipelines using GitLab CI.
Tech stack: python, pytest, gitlab-ci, jenkins, wiremock.
GSheet data export plugin
Companies analysts prefer to work with data using the most convenient tools. Once in my experience, this tool was Google GSheet (yeah, big data), not an expensive mature tool bought for this purpose. Common sense says tools are for people, not vice versa, so when a few dozen of analysts requested features to export data in the GSheet with minimal effort, I started work.
Looker data export
Exporting data from the Looker(BI) to GSheet with proper data security and authentication was developed. Now it is in use of a few teams of analysts.
Tech stack: JS, LookML, Chrome App Store, Gsheet, Looker.
Business Intelligence (BI) data engineering
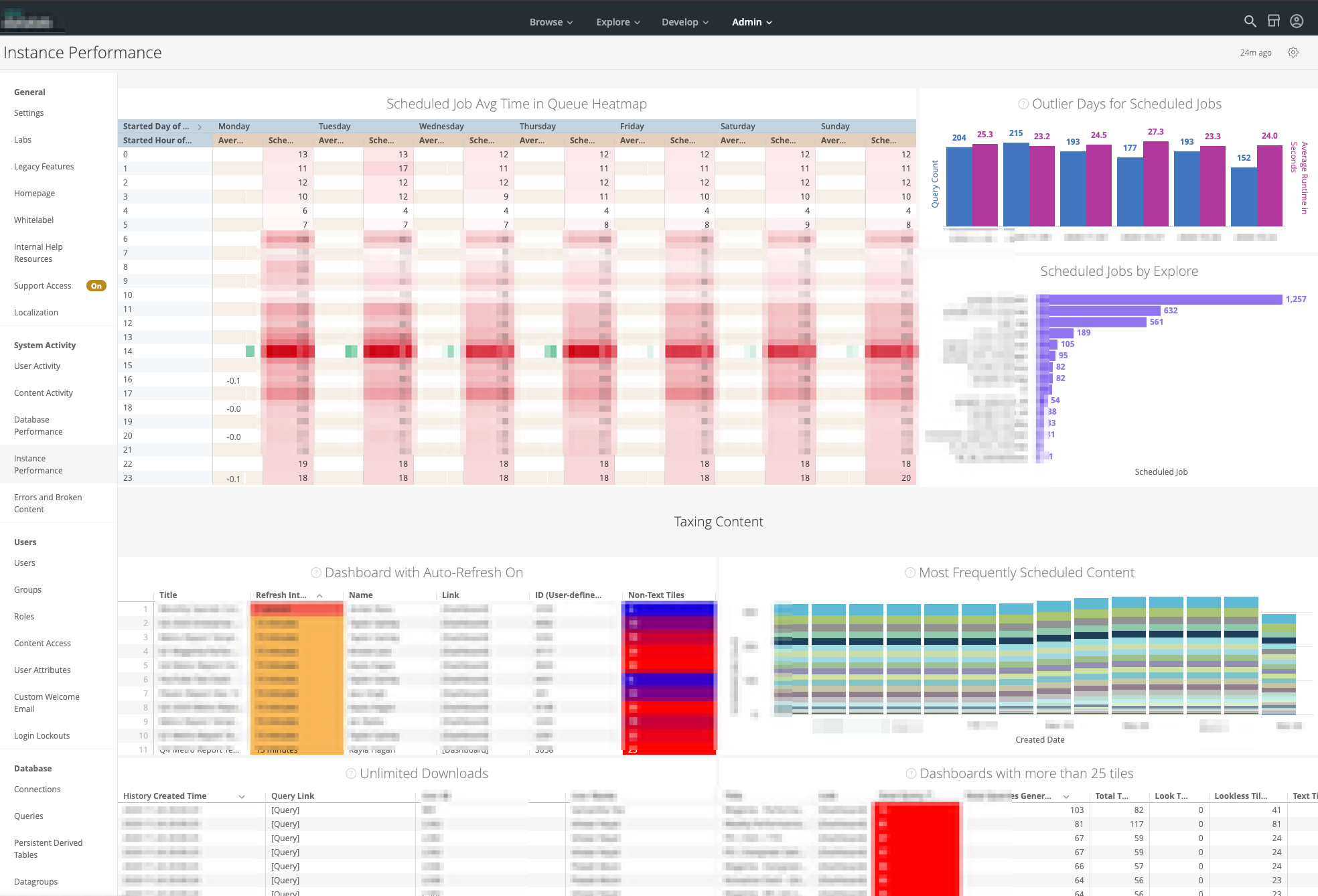
System activity dashboards
I implemented BI semantic layer using Looker and realized user-specific logic using LookML and SQL. Many SQL optimizations and performance tunings were done, a variety of BI dashboards for consumers were created.
Tech stack: Looker, LookML, SQL, Presto, Hive.
System monitoring dashboards
We had a few stages of data flow: ingestion, transformation, business metrics calculation, materialization. Things can go wrong in each of these stages (and they did:), resulting in inconsistent data, wrong values, irrelevant data, etc.
We wanted to make the system process visible for teams responsible for the maintenance and make our clients more confident in the data integrity.
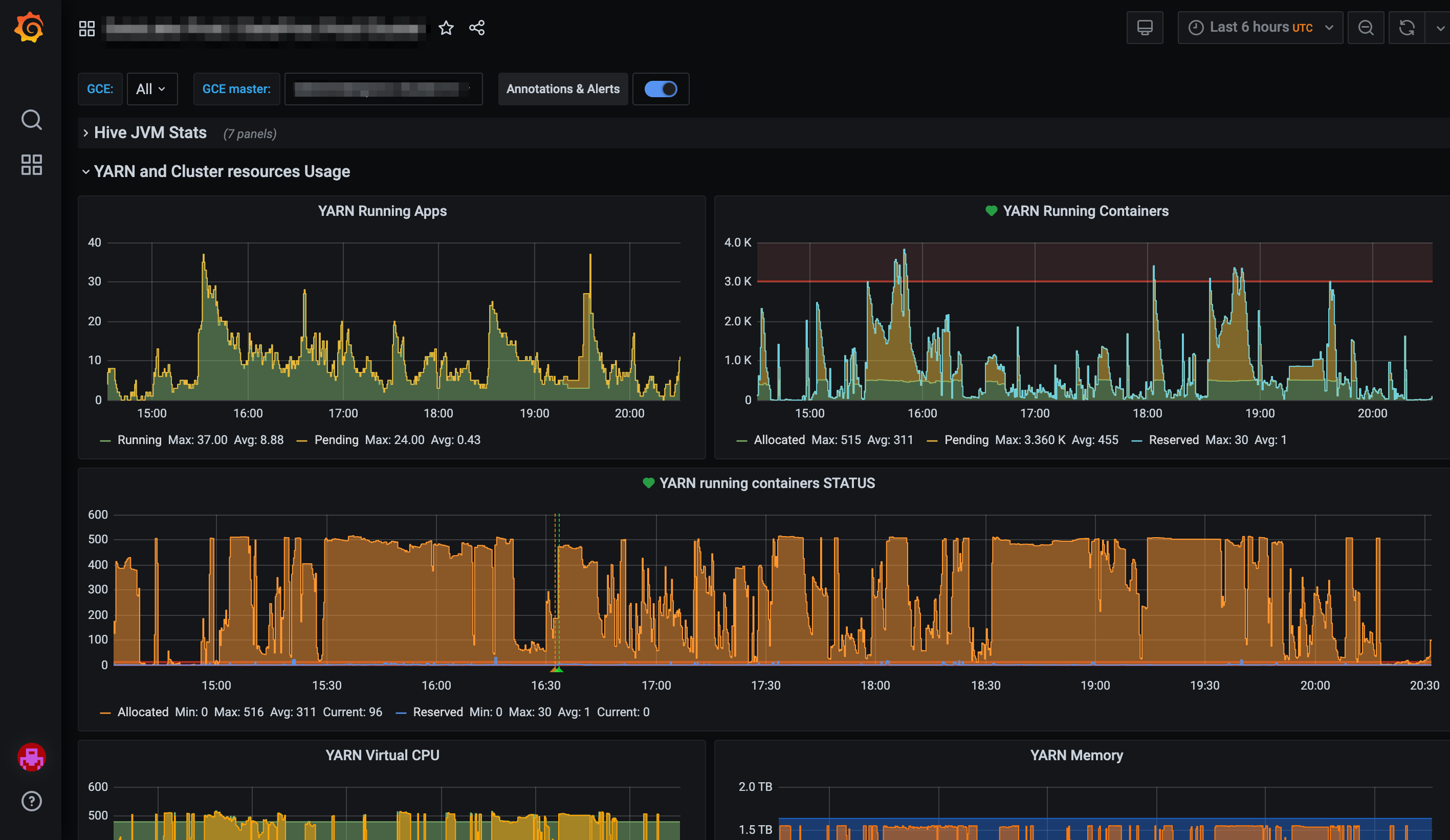
Big data components dashboards using Grafana
To achieve this, I’ve developed a series of dashboards, which show: data integrity, accuracy, freshness, ingestion, and transformation processes statuses.
Tech stack: stackdriver, BigQuery, SQL, Looker, LookML.
Summary
Big corporations have a specific nature by themselves. The common image is that corporations are soulless bureaucratic machines. Corporations indeed tend to standardize and minimize risks by delineating responsibilities. However, sometimes risk is a price.
In (tech) life, corporations are facing problems where they need a multi-skilled (T-shape?) person to solve them. In some cases, I was that person; it gave me wonderful opportunities to solve problems on the scale and make people’s lives easier, which I believe is a big thing.